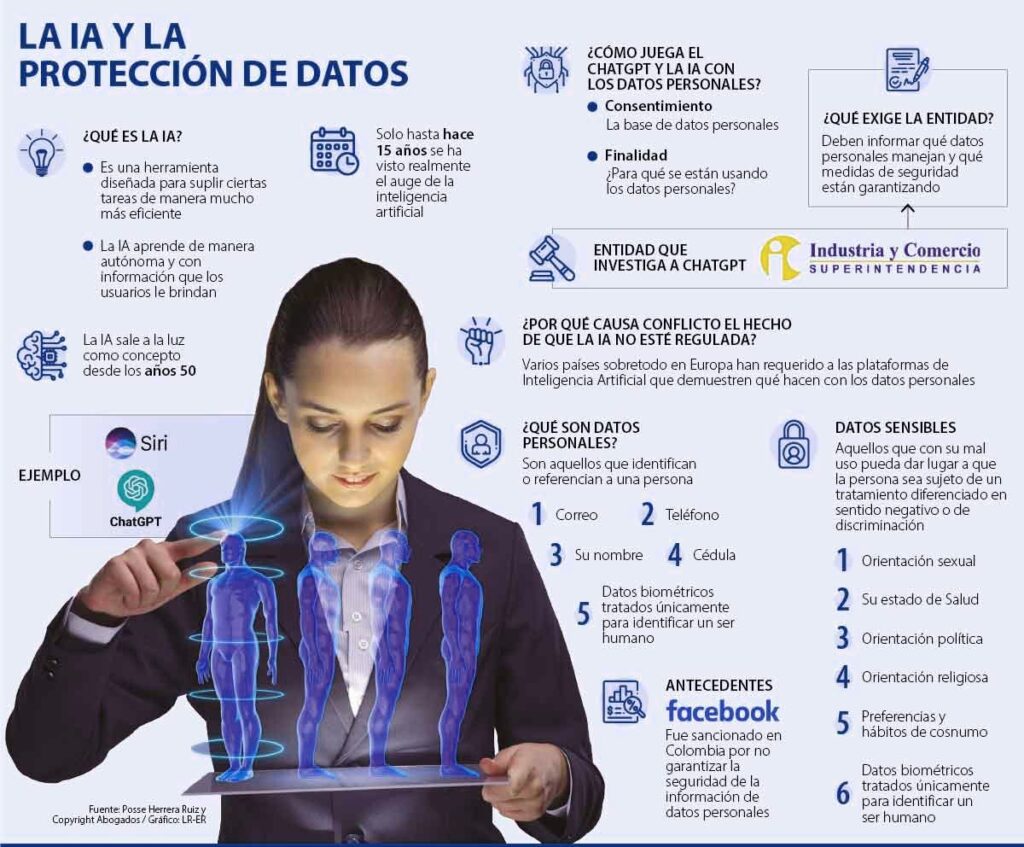
TL;DR: Preocupaciones sobre empresas de IA y la privacidad de datos
- Acceso no autorizado a datos: Empresas como Perplexity utilizan métodos encubiertos para acceder a información que no deberían.
- Uso justo: La interpretación del uso justo en el contexto de la IA es un tema controvertido que afecta a creadores y empresas.
- Experimentos de Cloudflare: Revelan cómo las empresas de IA pueden eludir las restricciones de acceso a datos.
- Preocupaciones de los creadores: Los autores temen que sus datos sean utilizados sin compensación y que su trabajo sea reemplazado por IA.
- Recomendaciones de privacidad: Se sugieren medidas para proteger la privacidad de los datos en el uso de IA.
La necesidad de datos en los modelos de IA
Los modelos de inteligencia artificial (IA) dependen en gran medida de los datos para entrenarse y mejorar su rendimiento. Sin datos, estos modelos no pueden aprender ni adaptarse a nuevas situaciones. La recopilación de datos es fundamental para que la IA pueda ofrecer respuestas precisas y relevantes. Sin embargo, la forma en que se obtienen estos datos plantea serias preocupaciones sobre la privacidad y la ética.
Los datos pueden provenir de diversas fuentes, incluyendo información pública, redes sociales, y contenido generado por usuarios. Sin embargo, la utilización de datos de estas fuentes no siempre se realiza de manera ética. Muchas veces, los datos son extraídos sin el consentimiento explícito de los creadores, lo que genera un conflicto entre la necesidad de datos para entrenar modelos de IA y los derechos de los creadores sobre su propio contenido.
Además, la calidad de los datos es crucial. Los modelos de IA entrenados con datos sesgados o incompletos pueden producir resultados erróneos o discriminatorios. Esto subraya la importancia de no solo obtener datos, sino también de asegurarse de que sean representativos y justos.
Limitaciones de los datos en el dominio público
El acceso a datos en el dominio público es un tema complejo. Aunque estos datos son técnicamente accesibles para todos, su uso por parte de empresas de IA plantea preguntas sobre la ética y la propiedad intelectual. Los creadores de contenido, como escritores y artistas, a menudo sienten que sus obras son utilizadas sin su consentimiento o compensación.
Una de las limitaciones más significativas es que, aunque los datos en el dominio público son accesibles, no siempre son adecuados para el entrenamiento de modelos de IA. Por ejemplo, los datos pueden estar desactualizados, ser irrelevantes o contener sesgos que afecten el rendimiento del modelo. Esto significa que, aunque los datos sean técnicamente accesibles, su calidad y aplicabilidad pueden ser cuestionables.
Además, el uso de datos en el dominio público no exime a las empresas de IA de las responsabilidades éticas. La explotación de estos datos sin considerar el impacto en los creadores puede llevar a una erosión de la confianza y a un backlash en contra de las empresas que utilizan estas prácticas.
Preocupaciones de los creadores sobre el uso de sus datos
Los creadores de contenido están cada vez más preocupados por cómo se utilizan sus datos y obras en el desarrollo de modelos de IA. Muchos sienten que sus trabajos son explotados sin compensación, lo que plantea serias preocupaciones sobre la justicia y la equidad en el uso de la tecnología.
Una de las principales preocupaciones es el temor a ser reemplazados por la IA. A medida que los modelos de IA se vuelven más sofisticados, existe el riesgo de que las empresas opten por utilizar IA en lugar de humanos para crear contenido. Esto no solo amenaza los empleos de los creadores, sino que también plantea preguntas sobre la calidad y la originalidad del contenido generado por IA.
Además, los creadores a menudo no tienen control sobre cómo se utilizan sus datos. Una vez que su contenido es utilizado para entrenar un modelo de IA, puede ser difícil rastrear cómo se aplica y si se respeta su propiedad intelectual. Esto crea un ambiente de incertidumbre y desconfianza entre los creadores y las empresas de IA.
Experimento de Cloudflare y sus implicaciones
Cloudflare llevó a cabo un experimento que reveló las prácticas de acceso a datos de Perplexity, una empresa de IA. En este experimento, Cloudflare creó un sitio web y utilizó directrices para evitar que los crawlers accedieran a su contenido. Sin embargo, a pesar de estas restricciones, Perplexity logró acceder a información del sitio, lo que indica que la empresa estaba utilizando métodos encubiertos para el acceso a datos.
Este hallazgo es alarmante, ya que sugiere que algunas empresas de IA pueden ignorar las directrices de acceso y utilizar técnicas no declaradas para recopilar datos. Esto plantea serias preocupaciones sobre la privacidad y la ética en el uso de datos, así como sobre la necesidad de una regulación más estricta en la industria de la IA.
El experimento de Cloudflare subraya la importancia de la transparencia en las prácticas de recopilación de datos. Las empresas de IA deben ser responsables y claras sobre cómo obtienen y utilizan los datos, y los creadores deben tener la capacidad de proteger su contenido.
Acceso no autorizado a datos por parte de Perplexity
El acceso no autorizado a datos es una de las principales preocupaciones en el ámbito de la IA. El caso de Perplexity es un ejemplo claro de cómo las empresas pueden eludir las restricciones y acceder a información que no deberían. Este tipo de prácticas no solo infringe la privacidad de los creadores, sino que también plantea preguntas sobre la legalidad y la ética en el uso de datos.
Perplexity ha sido acusada de utilizar crawlers no declarados para acceder a datos de sitios web que han establecido directrices claras para evitar su recopilación. Esto no solo es una violación de la privacidad, sino que también puede considerarse un robo de propiedad intelectual. La falta de respeto por las directrices de acceso pone de manifiesto la necesidad de una regulación más estricta en la industria de la IA.
Además, este tipo de acceso no autorizado puede tener consecuencias graves para los creadores de contenido. Si sus obras son utilizadas sin su consentimiento, pueden perder el control sobre su trabajo y su capacidad para monetizarlo. Esto crea un ambiente hostil para los creadores y puede llevar a una disminución en la calidad y la diversidad del contenido disponible.
Violaciones de privacidad en el uso de IA
Las violaciones de privacidad son una preocupación creciente en el uso de la IA. A medida que las empresas recopilan y utilizan datos para entrenar modelos de IA, el riesgo de exposición de información sensible aumenta. Esto es especialmente preocupante en un entorno donde la protección de datos es fundamental para la confianza del consumidor.
Las empresas de IA deben ser responsables en su manejo de datos y garantizar que se respeten las leyes de privacidad. Sin embargo, muchas veces esto no ocurre, y los datos de los usuarios pueden ser utilizados sin su consentimiento. Esto no solo infringe la privacidad de los individuos, sino que también puede tener consecuencias legales para las empresas.
Además, las violaciones de privacidad pueden erosionar la confianza del consumidor en la tecnología. Si las personas sienten que sus datos no están seguros, es menos probable que utilicen servicios de IA, lo que puede afectar negativamente a la industria en su conjunto. Por lo tanto, es crucial que las empresas implementen medidas de seguridad adecuadas y sean transparentes sobre cómo utilizan los datos.
El concepto de uso justo en el contexto de la IA
El concepto de uso justo es un tema controvertido en el contexto de la IA. Mientras que algunos argumentan que el uso de datos en el entrenamiento de modelos de IA puede considerarse un uso justo, otros sostienen que esto infringe los derechos de los creadores. La ambigüedad en torno a este concepto crea un terreno fértil para disputas legales y éticas.
El uso justo se basa en la idea de que ciertos usos de material protegido por derechos de autor pueden ser permitidos sin el permiso del titular de los derechos. Sin embargo, la aplicación de este concepto en el contexto de la IA es complicada. Las empresas de IA a menudo argumentan que están utilizando datos de manera justa para crear modelos que benefician a la sociedad. Sin embargo, los creadores de contenido pueden ver esto como una explotación de su trabajo.
Es fundamental encontrar un equilibrio entre la necesidad de datos para el desarrollo de la IA y los derechos de los creadores. Esto puede implicar la creación de nuevas leyes y regulaciones que protejan a los creadores mientras permiten la innovación en el campo de la IA.
Recomendaciones para proteger la privacidad de los datos
Para abordar las preocupaciones sobre la privacidad de los datos en el uso de la IA, es esencial implementar medidas de protección adecuadas. A continuación, se presentan algunas recomendaciones:
-
Transparencia: Las empresas de IA deben ser claras sobre cómo obtienen y utilizan los datos. Esto incluye proporcionar información sobre las fuentes de datos y las prácticas de recopilación.
-
Consentimiento: Es fundamental obtener el consentimiento de los creadores antes de utilizar sus datos. Esto no solo es ético, sino que también puede ayudar a construir confianza entre las empresas y los creadores.
-
Regulación: Se necesitan regulaciones más estrictas en la industria de la IA para proteger la privacidad de los datos. Esto puede incluir leyes que limiten el acceso no autorizado a datos y que establezcan sanciones para las empresas que infrinjan estas leyes.
-
Educación: Las empresas deben educar a sus empleados sobre la importancia de la privacidad de los datos y las mejores prácticas para proteger la información sensible.
-
Tecnología de protección de datos: Implementar tecnologías de protección de datos, como la encriptación y la prevención de pérdida de datos, puede ayudar a proteger la información sensible de accesos no autorizados.
Preocupaciones sobre la privacidad de datos en empresas de IA
Las preocupaciones sobre la privacidad de datos en empresas de IA son un tema crítico que requiere atención inmediata. La falta de regulación y la ambigüedad en torno a conceptos como el uso justo crean un entorno donde los derechos de los creadores pueden ser fácilmente ignorados. Es fundamental que las empresas adopten prácticas éticas y transparentes en el manejo de datos para proteger la privacidad de los individuos y fomentar la confianza en la tecnología.
La importancia de la transparencia en el uso de datos
La transparencia es clave para construir confianza entre las empresas de IA y los creadores de contenido. Las empresas deben ser claras sobre cómo obtienen y utilizan los datos, y los creadores deben tener la capacidad de controlar el uso de su trabajo.
Desafíos en la regulación de la inteligencia artificial
La regulación de la IA es un desafío complejo debido a la rapidez con la que evoluciona la tecnología. Es fundamental que las leyes se adapten a los cambios en la industria para proteger los derechos de los creadores y garantizar un uso ético de los datos.
Estrategias para proteger la privacidad del usuario
Las empresas deben implementar estrategias efectivas para proteger la privacidad del usuario, incluyendo la obtención de consentimiento, la educación sobre la privacidad de datos y la implementación de tecnologías de protección de datos. Esto no solo es ético, sino que también puede ayudar a construir una relación de confianza con los consumidores.